
Résoudre les Hallucinations
Pourquoi les LLMs plus large ne sont pas toujours meilleurs



Bonjour à tous !
Dans le domaine de l'IA, la tendance générale a été d'agrandir les modèles de langage de plus en plus. L'hypothèse est qu’un modèle plus grand peut mieux généraliser et donc améliorer la précision factuelle. Il y a un problème : les LLMs ne sont pas principalement conçus pour stocker des informations factuelles. Leur véritable force réside dans la génération de texte cohérent et structuré, basée sur les exemples appris pendant l’entraînement. Cependant, une récente étude démontre qu’augmenter la taille des GLMs pour réduire les erreurs factuelles n'est pas la meilleure voie à suivre.
Le problème des modèles plus grands pour la précision factuelle
Les gens critiquent souvent les LLMs pour leurs erreurs factuelles, affirmant qu'ils sont « inutiles » à cause des incohérences factuelles (aussi appelées hallucinations). Pourtant, les erreurs factuelles ne sont pas une erreur des LLMs. Le but d'un LLM est la génération de texte et ses connaissances se limitent aux données sur lesquelles il a été entraîné. Ce qui implique qu'il manquera toujours les dernières mises à jour (temps réel). Malgré cela, les entreprises poussent à des modèles de plus en plus grands, espérant que le grand nombre d'exemples réduira les hallucinations.
💡 Oui, augmenter le nombre de paramètres aide à réduire les hallucinations. Mais est-ce une utilisation efficace des ordinateurs ?Un inconvénient majeur de ces modèles massifs est leur incapacité à rester à jour. Étant donné que leurs connaissances sont en grande partie figées au moment de la formation, ils deviennent rapidement obsolètes, surtout lorsqu'ils traitent de domaines en constante évolution tels que les événements actuels, la médecine ou la technologie. Mettre à jour ces modèles n’est pas aussi simple que de cliquer sur « rafraîchir ». C’est un processus coûteux et long qui nécessite de réentraîner tout le modèle. En conséquence, plus le modèle est grand, plus il est susceptible de présenter des informations obsolètes ou inexactes.
L'approche consistant à faire croître les modèles pour réduire les hallucinations pose également un problème, car une grande partie de la puissance de calcul du modèle est utilisée de manière inefficace. Au lieu d'incorporer directement un grand nombre d'exemples dans les poids du modèle, nous devrions concentrer nos efforts sur l'amélioration de la capacité du modèle à reconnaître des modèles et à raisonner efficacement. Un modèle plus petit, bien que potentiellement moins précis en termes de mémorisation, peut tirer parti de meilleures capacités de raisonnement pour un coût moindre, le rendant nettement plus efficace qu'un modèle plus grand qui repose lourdement sur la rétention de connaissances par la force brute.
Mais un problème demeure… Comment peut-on "assurer" la précision factuelle avec des modèles plus petits ?
Solution ? Génération augmentée d’information application (RAG)!
Avec le RAG, nous pouvons nous éloigner de la nécessité de modèles massifs. RAG combine les capacités génératives de modèles potentiellement plus petits avec la possibilité de récupérer des informations précises et à jour à partir de sources externes. Cette approche enlève la charge de la précision factuelle du LLM et lui permet de se concentrer sur ce qu’il fait de mieux : la génération de texte.
Les modèles de langage plus petits, lorsqu'ils sont combinés à la récupération de connaissances externes, peuvent égaler, voire surpasser, la performance de modèles beaucoup plus grands dans des tâches qui dépendent fortement des faits précis. Cet avantage découle du fait que les modèles plus petits sont plus faciles à entraîner et à affiner, les rendant plus efficaces. En réduisant la taille du modèle, le temps nécessaire à l’entraînement diminue considérablement et le processus d’ajustement devient plus simple, nécessitant moins de ressources au total. Cette approche est non seulement plus efficace, mais aussi plus rentable.
De plus, l’utilisation de techniques comme RAG améliore encore la performance des modèles plus petits. Alors que les modèles plus grands prennent souvent plus de temps lors de l’inférence en raison de la nécessité de traiter de nombreux paramètres, les modèles plus petits avec RAG peuvent être plus rapides et plus précis. Cela est dû au fait qu’ils ne se reposent pas uniquement sur des connaissances internes au modèle. Ils récupèrent des faits pertinents de manière dynamique.
La précision des informations factuelles s'améliore considérablement grâce à ce processus. En s'appuyant sur des sources fiables en temps réel, RAG aide à empêcher le modèle de générer des informations trompeuses ou incorrectes, un problème courant chez les modèles plus grands qui peuvent s'appuyer sur des données obsolètes ou incomplètes. Cette combinaison de modèles plus petits et de récupération en temps réel crée un système plus robuste et précis, minimisant les erreurs et améliorant les performances dans les tâches dépendantes des faits.
💡 Le point faible des petits modèles
Bien que les petits modèles excellent en efficacité et en précision grâce à la récupération externe, ils peuvent être moins aptes à suivre des instructions complexes directement issues de l'invite. Cela signifie qu'ils peuvent nécessiter une ingénierie supplémentaire pour gérer certaines tâches avant de générer des réponses. Par exemple, si vous demandez dans une invite de faire une recherche dans une base de données et s’il ne trouve rien, de rechercher sur internet, puis de transformer le texte en sortie en JSON et d’ajouter un lien, etc. Un grand modèle sera peut-être en mesure de suivre toutes les instructions, tandis qu’un petit modèle aura beaucoup de difficulté. Il faut diviser l’invite en plusieurs tâches unitaires et utiliser de la logique informatique.Généralisation vs Précision factuelle
Il est important de comprendre que bien que les LLMs sont bons pour la généralisation,* mais ils ne sont pas nécessairement l’outil adéquat pour améliorer la précision factuelle. La généralisation permet aux modèles de comprendre des modèles et de générer un texte fluide, mais cela ne garantit pas que le texte généré sera toujours factuellement correct. Au lieu d’augmenter la taille des modèles pour obtenir de meilleurs résultats factuels, nous devrions nous concentrer sur des systèmes hybrides utilisant des techniques comme RAG, qui équilibrent généralisation et récupération de faits précis.
*LLM (large language modèle) est un mot bien ambigu, maintenant qu’il y a plusieurs grandeurs de ”grand” modèle de langue!
Dans un rapport récent de l’équipe Salesforce, ils démontrent un exemple parfait d’amélioration de la précision factuelle sans augmenter la taille. SFR-RAG, un petit modèle (9 milliards de paramètres “petit” par rapport aux standards actuels) mais très efficace. SFR-RAG est spécifiquement conçu pour maximiser les avantages de RAG via la génération fondée sur le contexte, minimisant les hallucinations et gérant des scénarios complexes tels que les informations contradictoires ou les questions sans réponse.
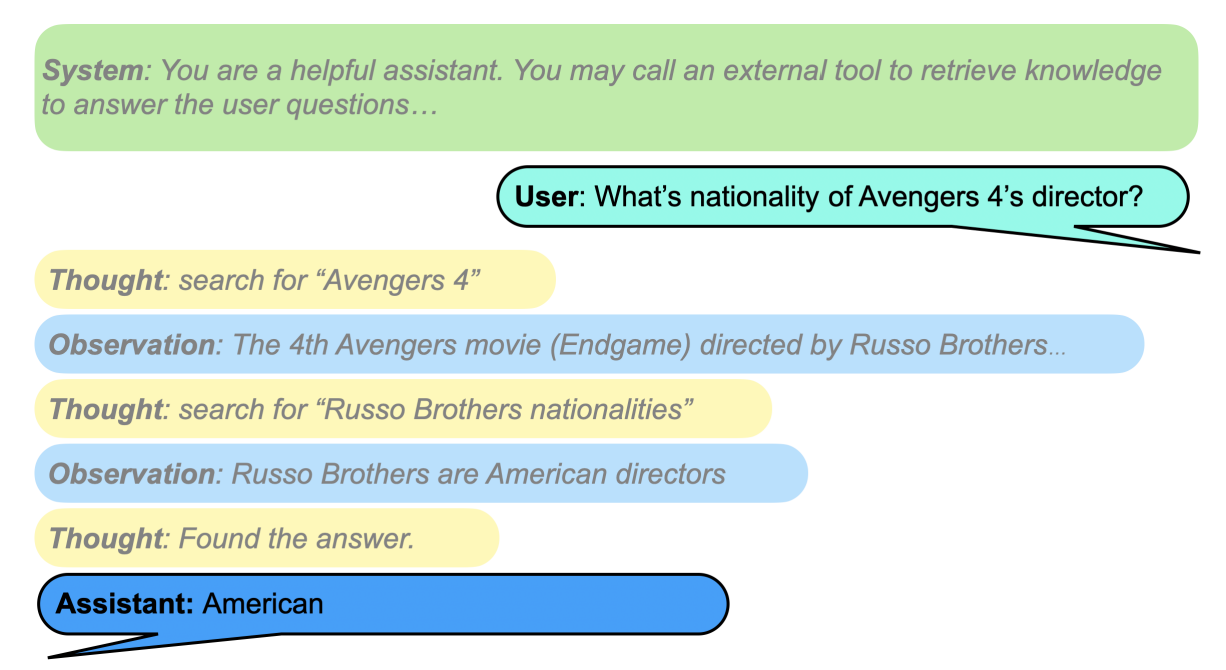
L'innovation clé de SFR-RAG par rapport aux systèmes RAG traditionnels est l'introduction de Pensées et Observations, où le modèle génère une chaîne de raisonnement interne (similaire à comment fonctionne O1 d’OpenAI). Cela permet un raisonnement en plusieurs étapes, permettant au modèle d’identifier des lacunes dans l'information et d’utiliser des outils pour récupérer des données supplémentaires à partir de sources externes.
Ils ont conçu le système pour distinguer les pensées et les observations en utilisant des jetons spécifiques pour marquer les limites de chaque section. Cette méthode permet d’entraîner le modèle à générer spécifiquement des pensées tout en s'appuyant sur un système de récupération pour obtenir les informations nécessaires.
SFR-RAG représente un changement par rapport à l’approche RAG conventionnelle, où les informations pertinentes sont simplement ajoutées à l’invite initiale. Au lieu de cela, il utilise le LLM pour générer des requêtes de recherche ciblées pour les informations manquantes, tout en affinant le modèle pour produire des pensées de haute qualité servant de requêtes de recherche efficaces.
Bien que cette approche puisse prendre un peu plus de temps à exécuter, l'avantage réside dans l'utilisation d'un modèle plus petit, plus rapide à entraîner, capable de correspondre ou même de surpasser la performance de modèles beaucoup plus grands.
💡 Ce système de pensée reflète les dernières avancées dans les modèles d’OpenAI, où des chaînes de pensées automatisées imitent les étapes logiques que nous effectuons généralement manuellement avec ces systèmes.Conclusion
L'avenir de l'IA ne doit pas forcément se résumer à augmenter la taille des modèles. En réalité, les LLMs plus petits combinés à des mécanismes de récupération comme SFR-RAG offrent une approche plus intelligente et plus efficace pour maintenir la précision tout en réduisant les coûts liés à l’entraînement et à l’inférence. L'essentiel est de laisser les LLMs faire ce qu’ils font de mieux : générer du texte, tout en s'appuyant sur des systèmes externes comme RAG pour fournir les informations factuelles. Il est temps de déplacer notre attention vers une approche plus équilibrée et évolutive du développement de l’IA, qui combine les forces des modèles plus petits avec des systèmes de récupération performants.